
Auf meiner Suche nach Sinn und Bedeutung des Turing-Tests habe ich zunächst untersucht, wie genau der Turing-Test funktioniert.
In diesem Artikel soll es um die Rezeption des Turing-Test und die bis heute andauernde Diskussion darüber gehen. Über den Turing-Test wurde enorm viel geschrieben. Robert French bezeichnete Turings Artikel sogar mal als den meistdiskutierten in der gesamten Geschichte der KI[1]French, Robert M. (2000): The Turing Test: the first 50 years. In: Trends in cognitive sciences 4 (3), S. 115–122.. Es wird mir also unmöglich sein, die gesamte bisherige Rezeption des Turing-Test hier zusammenzufassen.
Für alle, die tiefer in das Thema einsteigen möchten, empfehle ich das Sammelwerk „Parsing the Turing test“ (2009)[2]Epstein, Robert; Roberts, Gary; Beber, Grace (Hg.) (2009): Parsing the Turing test. Philosophical and methodological issues in the quest for the thinking computer: Springer., sowie den Artikel „Turing test: 50 years later“ der eine detaillierte Zusammenfassung der Diskussion bis 2000 bietet[3]Saygin, Ayse Pinar; Cicekli, Ilyas; Akman, Varol (2000): Turing test: 50 years later. In: Minds & Machines 10 (4), S. 463–518..
Wie wurde der Test interpretiert?
Neben viel (anfänglicher) Begeisterung gab es viel Kritik am Turing-Test. Einige Interpretationen möchte ich darstellen. Ganz grob kann ich diese in 4 Kategorien unterteilen.
- Die klassische Interpretation – bei Turings Zeitgenossen und Nachfolgern wurde der Test überwiegend positiv aufgenommen (siehe z. B. Weizenbaum[4]Weizenbaum, Joseph (1966): ELIZA — a Computer Program for the Study of Natural Language Communication Between Man and Machine. In: Commun. ACM 9 (1), S. 36–45. DOI: 10.1145/365153.365168. ).
- Die Kritiker – Einige Jahrzehnte nach Turing wurde klar, dass sich KI-Forschung anders entwickelt als zu Turings Zeit erwartet. Entsprechend erschien der Test mehr und mehr aus der Zeit gefallen (siehe z. B. Hayes und Ford[5]Hayes, Patrick; Ford, Kenneth (1995): Turing test considered harmful. In: IJCAI (1), S. 972–977 ).
- Die Orthodoxie – Einige lassen die Kritik nicht gelten und verteidigen die „reine Lehre“ wie Turing sie angeblich gemeint habe. Für diese Interpretation gibt es nur einen „echten“ Turing-Test (siehe z. B. Moor[6]Moor, James H. (2001): The status and future of the Turing test. In: Minds & Machines 11 (1), S. 77–93.).
- Weiterentwicklung – Immer wieder wurde versucht, den ursprünglichen Test zu erweitern und anzupassen. Für diese Interpretation ist der Turing-Test eine ganze Familie von Methoden (siehe z. B. Hernández-Orallo[7]Hernández-Orallo, José (2000): Beyond the Turing test. In: Journal of Logic, Language and Information 9 (4), S. 447–466.).
Im Folgenden schaue ich mir einige Standpunkte zum Turing-Test näher an.
Kritik am Turing-Test
Das Chinesische Zimmer (Searle)
Eine der machtvollsten Kritiken kam 1980 in Form eines Gedankenexperiments von John Searle[8]Searle, John R. (1980): Minds, brains, and programs. In: Behavioral and brain sciences 3 (3), S. 417–424.. Nach unserem bisherigen Verständnis (und das hat sich seitdem nicht geändert) können wir KI entwickeln, die als Werkzeug für Menschen und Ihre Absichten dient, aber wir können (noch) keine KI entwickeln, die denken und verstehen kann, wie ein Mensch (und eigene Absichten verfolgt). Es mag also möglich sein, eine Maschine zu entwickeln, die sprachliche Hürden überwindet und sich in einer Konversation angemessen verhält – dies allein gäbe aber nicht mal ansatzweise einen Hinweis auf menschenähnliche Intelligenz oder menschenähnliches Verstehen. Insofern könne auch ein erfolgreich bestandener Turing-Test nicht als hinreichende Begründung oder Indiz für menschenähnliche Intelligenz einer Maschine gelten.
Sein Gedankenexperiment sieht so aus:
Ein Person sitzt allein in einem Zimmer. Die Person spricht sehr gut Englisch spricht aber überhaupt kein Chinesisch. Von außen kommen Text-Nachrichten herein und die Person kann ihre Antworten zurück nach draußen reichen. Manchen Nachrichten von außen sind in Englisch und die Person kann sie selbst beantworten. Andere Nachrichten sind dagegen auf Chinesisch und die Person kann sie nicht selbst beantworten. In dem Zimmer gibt es aber einige Handbücher mit englischsprachigen Anweisungen, wie auf bestimmte chinesische Nachrichten richtig zu antworten ist. Die Person kann zwar die chinesischen Nachrichten nicht lesen, aber mit Hilfe der Handbücher adäquate Antworten auf Chinesisch verfassen. Von außen sieht es so aus, also würde die Person im Zimmer sowohl Englisch als auch Chinesisch verstehen. Tatsächlich versteht die Person im Zimmer aber von der chinesisch-sprachigen Konversation kein Wort.
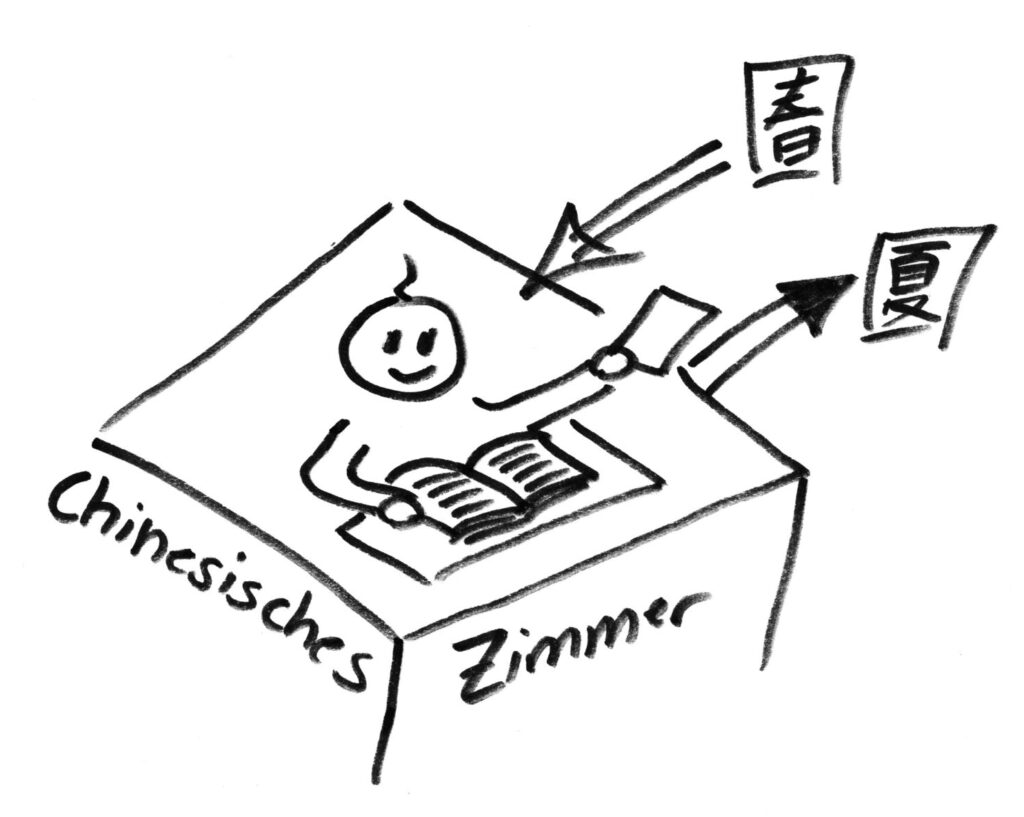
Die Person verhält sich, so Searle, was das Chinesisch betrifft wie ein Computer. Sie arbeitet einfach die Antworten nach einem Programm ab, ohne den Sinn dahinter wirklich zu verstehen,
Searles Kritik wurde selbst wieder heftig von vielen Seiten kritisiert – wozu Searle in vielen Fällen wieder Stellung bezogen hat. Sein Argument vom „Chinesischen Zimmer“ ist bis heute einer der wichtigsten und bekanntesten Bausteine in der Kritik des Turing-Tests (und bildet unter anderem die Basis für den unten genannten „Lovelace-Test“).
Die große Ablenkung (Whitby, Hayes, Ford)
Eine wesentliche Kritik am Turing-Test war und ist, dass er zwar zu seiner Zeit nützlich war, aber dies nicht länger ist. Hayes und Ford veröffentlichten 1995 einen Artikel, in dem sie den Turing-Test sogar als schädlich abqualifizierten[9]Hayes, Patrick; Ford, Kenneth (1995): Turing test considered harmful. In: IJCAI (1), S. 972–977. Sehr klar formulierte diese Kritik auch Whitby. Nach seiner anfänglich inspirierenden Wirkung sei der Turing-Test nach und nach zu einer Ablenkung von vielversprechenderen Forschungsansätzen verkommen. Er beschreibt die Beziehung zwischen KI-Forschung und dem Turing-Test so:
1950–1966: A source of inspiration for all concerned with AI.
1966–1973: A distraction from some more promising avenues of AI research.
1973–1990: By now a source of distraction mainly to philosophers, rather than AI workers.
1990 onwards: Consigned to history.[10]Whitby, Blay (1996): The turing test: AI’s biggest blind alley?’. In: Machines and thought: The legacy of Alan Turing 1, S. 53–62.
Turing hat in seinem Artikel weit in die Zukunft geblickt und es überrascht daher nicht, dass er mit einigen Ideen ziemlich daneben lag. Sowohl Turing selbst, als auch viele seiner Nachfolger in der KI-Forschung gingen davon aus, dass „menschenähnliche“ KI nur einen Steinwurf entfernt sei. Turing gibt in seinem Artikel im Abschnitt über „Learning Machines“ sehr klar Auskunft darüber, wie er sich eine lernende Maschine vorstellt. Dort lesen wir etwa:
Presumably the child-brain is something like a notebook as one buys it from the stationer’s. Rather little mechanism, and lots of blank sheets[11]Turing, Alan M. (1950): Computing machinery and intelligence. In: Mind 59 (236), S. 433–460..
Bereits 1976 hat Weizenbau einer solchen, allzu simplifizierenden, Sicht auf den menschlichen Geist eine Absage erteilt – damals immernoch entgegen der herrschenden Vorstellung[12]Weizenbaum, Joseph (1978): Die Macht der Computer und die Ohnmacht der Vernunft. 1. Aufl. Frankfurt am Main: Suhrkamp (Suhrkamp-Taschenbücher Wissenschaft, 274).. Nun gibt es aber bis heute keine nennenswert „menschenähnliche“ KI. Daher, so die Kritiker, sei auch keine Notwendigkeit gegeben für einen entsprechenden Test – der Turing-Test daher nutzlos.
Kritik am Ursprungstext
Ein absolut berechtigte Kritik zielt auf den Ursprungstext von Alan Turing. Dieser ist an vielen Stellen ungenau, unklar und mehrdeutig. Darauf haben unter anderem Bringsjord[13]Bringsjord, Selmer (2009): If I Were Judge. In: Robert Epstein, Gary Roberts und Grace Beber (Hg.): Parsing the Turing test. Philosophical and methodological issues in the quest for the thinking … Continue reading, sowie Ford, Glymour und Hayes[14]Turing, Alan M. (2009): Computing machinery and intelligence (Commented). Philosophical and methodological issues in the quest for the thinking computer. In: Robert Epstein, Gary Roberts und Grace … Continue reading hingewiesen. Angesichts dieser Unklarheit versuchen sie den Text maßvoll, aber nicht immer wortwörtlich zu interpretieren.
Gesagt oder gemeint? Die Intentionalitäts-Falle
Besonders einige Verteidiger des „(Standard) Turing-Test“ verweisen immer wieder auf das, was Turing angeblich gemeint habe. Diese Argumentationsweise ist problematisch (auch als „intentional fallacy“ bekannt), da wir Turing heute nicht mehr fragen können, was er „wirklich“ gemeint hat, und Turings Artikel auch Implikationen enthalten kann, die Turing selbst vielleicht gar nicht klar waren. Unter anderem Sterrett[15]Sterrett, Susan G. (2000): Turing’s two tests for intelligence. In: Minds & Machines 10 (4), S. 541–559. DOI: 10.1023/A:1011242120015. und Harnad[16]Harnad, Stevan (2000): Minds, Machines and Turing. In: Journal of Logic, Language and Information (9), S. 425–445. haben deutlich darauf hingewiesen, dass man besser genau schauen sollte, was Turing geschrieben hat, anstatt zu vermuten was er damit gemeint haben könnte.
Viele Autoren sind (zumindest teilweise) dennoch in diese Argumentsweise geraten. Hier ein Beispiel von Moor. Er erörtert einige unklare Textstellen. Leider versucht er dann krampfhaft Turing’s angebliche Absichten dahinter zu erahnen und zu begründen:
„Should we not assume“
„What he is suggesting is“
„evidence strongly indicates Turing had […] the standard interpretation […] in mind“
„his order of presentation leads naturally to the standard interpretation“
„if it was intended at all“[17]Moor, James H. (2001): The status and future of the Turing test. In: Minds & Machines 11 (1), S. 77–93.
Es nimmt mir teilweise geradezu religiöse Züge an, wenn auf Turing immer wieder als höchste Autorität verwiesen und seine Aussagen als Begründungen herangeführt werden:
„Turing himself“
„Turing had a vision“
„Alan Turing begins […] with a clever philosophical move“
„what does Turing intend“
„Turing states […] Turing discusses […] Turing says […] Turing focusses […] Turing gives […] Turing continues […] Turing explains […]“[18]Moor, James H. (2001): The status and future of the Turing test. In: Minds & Machines 11 (1), S. 77–93.
Ähnlich ist auch eine Argumentation bei Warwick und Shah zu lesen, die zwar einräumen, dass es verschiedene Interpretationen des Turing-Tests gibt und der Original-Text reichlich unklar bleibt, aber am Ende (mit Bezug auf Turings Absichten) beschließen, dass nur eine einzige Interpretation die richtige sein könne[19]Warwick, Kevin; Shah, Huma (2016): Passing the turing test does not mean the end of humanity. In: Cognitive computation 8 (3), S. 409–419..
Weiterentwicklungen der Turing-Tests
Zwischen dogmatischer Begeisterung für Turings ursprüngliche Idee und der generellen Ablehung des Turing-Tests als nützliche Methode bildete sich eine dritte Richtung heraus. Ihr liegen zwei Annahmen zu Grunde:
- Der Turing-Test ist nicht ein ganz bestimmter Test, sondern eine ganze Familie von verschiedenen Turing-Tests (wovon der „(Standard) Turing-Test“ und das „Imitation Game“ nur zwei Varianten sind).
- Auf der Basis von Kritik am Turing-Test können bessere Turing-Tests entwickelt werden (welche natürlich auch weiter kritisiert und verbessert werden können).
Die TT-Hierarchie (Harnad)
Stevan Harnad versucht den Turing-Test in einen größeren Zusammenhang zu setzen. Eine Maschine die den Turing-Test besteht sei in einem ganz streng abgegrenzten Bereich nicht von einem Menschen zu unterscheiden. Es entsteht ein System, eine Hierarchie von Tests, die diesen abgegrenzten Bereich sukzessive erweitern…
- Die unterste Ebene wäre ein „Test“ (eher eine Art Untersuchung) für Maschinen, die leicht von einem Menschen unterscheidbar sind (auch wenn sie vielleicht erste Ähnlichkeiten aufweisen), Harnad nennt diese Stufe „t1“ (t für „toy“, also „Spielzeug„).
- Auf der zweiten Ebene „T2“ (für „Turing“) sieht Harnad den von Alan Turing vorgeschlagenen Test. Beim Austausch von Symbolen (=Sprache) ist die Maschine, die diesen Test besteht, vom Menschen nicht unterscheidbar. So eine Maschine hätte Ähnlichkeit mit einer Brieffreundin, die wir nie in Person treffen, sondern mit der wir nur über Briefe oder Nachrichten kommunizieren.
- Einen Test der Ebene „T3“ würden Maschinen bestehen, die nicht nur Sprache beherrschen, sondern auch äußerlich vom Menschen nicht mehr zu unterscheiden sind. Zwar würde eine (innere) Untersuchung sofort zeigen, dass es sich um eine Maschine handelt, doch in Alltagssituationen wären solche Maschinen von Menschen funktional nicht zu unterscheiden.
- Den Test der Ebene „T4“ könnte laut Harnad nur eine Maschinen bestehen, die nicht nur von außen, sondern auch von innen vom Menschen nicht unterscheidbar wäre (die also Blut, Knochen, etc. aufweisen würde). Nur mit aufwändigen Analysemethoden würde man diese Maschine als solche entlarven könnne.
- Im letzten Test der Ebene „T5“ entsteht die vollkommenen Un-Unterscheidbarkeit zwischen Mensch und Maschine. Eine Maschine, die mit keiner Analysemethode vom Menschen unterscheidbar wäre (also eine Art künstlicher Mensch) würde diesen Test bestehen.

Die 5 Ebenen decken also das gesamte Spektrum von „Ähnlichkeit“ ab (von „nicht ähnlich“ bis „ununterscheidbar“). Dabei ist „t1“ eher trivial und „T4 – T5“ liegen (wenn überhaupt) in weiter Zukunft. Harnad hat auf die Bedeutung von „“T3“ für die aktuelle Wissenschaft verwiesen.[20]Harnad, Stevan (1994): Levels of functional equivalence in reverse bioengineering. In: Artificial Life 1 (3), S. 293–301.[21]Harnad, Stevan (2000): Minds, Machines and Turing. In: Journal of Logic, Language and Information (9), S. 425–445.
Lovelace-Test
Der „Lovelace-Test“ ist im Grunde kein wirklicher Test, sondern ein unterstützendes Argument für Searles oben genanntes „Chinesisches Zimmer“. Es ist ein weiteres Gedankenexperiment in Gestalt eines Tests, welches die Messlatte für künstliche Intelligenz ein wenig nach oben rückt. Der Test ist leicht erklärt:
„Eine Maschine besteht den Lovelace-Test, wenn sie etwas beeindruckendes (sinnvoll und wiederholbar) erzeugt und ihr Konstrukteur/Programmierer nicht erklären kann, wie sie das geschafft hat.“[22]Bringsjord, Selmer; Bello, Paul; Ferrucci, David (2001): Creativity, the Turing test, and the (better) Lovelace test. In: Minds and machines (11), S. 3–27.
Nach dem Verständnis der Autoren (und auch meinem) sucht man nach einer solchen Maschine heute vergeblich (es geht nicht nur darum, dass Entwickler nicht mehr präzise nachvollziehen können, wie ein System zu bestimmten Ergebnissen kommt, wie bei manchen neuronalen Netzen), aber es wenn es sie gäbe, wäre ein bestandener Lovelace-Test wirklich ein gutes Indiz für „kreative“ Maschinen.
Erweiterte Turing-Tests am Beispiel des „QTT“
Eine interessante Variante eines erweiterten Turing-Tests ist der „Questioning Turing-Test“. Damassino dreht die Rollen in der Konversation um. Anstatt eine richtige Antwort zu geben, muss die Maschine die richtigen Fragen stellen. Die Maschine wird von einem menschlichen Prüfer daraufhin nach verschiedenen Kriterien bewertet[23]Damassino, Nicola (2020): The Questioning Turing Test. In: Minds & Machines 30 (4), S. 563–587. DOI: 10.1007/s11023-020-09551-6.. Insgesamt zeigen Damassinos Versuche und Untersuchungen für mich zwei Dinge: (1) eine Erweiterung und Optimierung des Turing-Tests führt wirklich zu besseren Ergebnissen, (2) es gibt auch in den 2020er Jahren weiter Interesse am Turing-Test und aktive Versuche ihn sinnvoll einzusetzen.
CAPTCHA
Eine der interessantesten, weil praktisch nützlichen, Weiterentwicklung des Turing-Test ist das „CAPTCHA“.
Diskussionen um den Turing-Test werfen immer wieder eine wichtige Frage auf: brauchen wir überhaupt einen praktischen Turing-Test? Stehen wir schon in dem Dilemma, entscheiden zu müssen wer Mensch ist und wer Maschine?
Heutzutage gibt es tatsächlich schon viele Maschinen, die versuchen als Menschen durchzugehen. Vor allem sogenannte „Spambots“ versuchen im Internet automatisiert Foren und Kommentarfelder mit Werbung zu füllen und sich dabei als Menschen ausgeben. Ein entsprechender „Turing-Test“ ist an dieser Stelle enorm nützlich, um z. B. Foren oder andere Funktionen im Internet vor Spambots zu schützen. Dies führte zur Entwicklungs des „CAPTCHA“[24]Ahn, Luis von; Blum, Manuel; Hopper, Nicholas J.; Langford, John (2003): CAPTCHA: Using hard AI problems for security. In: International conference on the theory and applications of cryptographic … Continue reading, einer Art automatisiertem Turing-Test (wobei es meistens darum geht, Bilder-Rätseln zu lösen).
Praktische Turing-Tests
Zunächst war der Turing-Test nur ein Gedankenexperiment, und wird bist heute meist als solches betrachtet. Aber man kann Turing-Tests ja auch ganz praktisch durchführen.
Der erste „Chatbot“, also eine Maschine die in natürlicher Sprache kommunizieren kann, war die 1966 präsentierte ELIZA. Seitdem gab es immer wieder medial inszenierte praktische Turing-Tests.
Besondere Bekanntheit erlangte der „Loebner-Preis“, bei dem seit 1990 die neusten Chatbots gegeneinander antraten. Es ging weniger um einen wissenschaftlichen Test, sondern um einen Wettbewerb verschiedener Chatbots. Die Tests wurden mit starken Begrenzungen durchgeführt, was Zeitraum und erlaubte Fragen durch die Jury angeht. Man kann wohl mit Sicherheit sagen, dass der „Loebner-Preis“ zur Popularität und Entwicklung von Chatbots beigetragen hat[25]Mauldin, Michael L. (1994): Chatterbots, tinymuds, and the turing test: Entering the loebner prize competition. In: AAAI, Bd. 94, S. 16–21.. Sein Nutzen für die KI-Forschung insgesamt wurde allerdings von Beginn an stark bezweifelt[26]Shieber, Stuart M. (1992): Lessons from a restricted turing test. Cambridge, Mass.: Center for Research in Computing Techn. Aiken Computation Laboratory Univ (TR / Center for Research in Computing … Continue reading.
Ähnliches gilt für einen Turing-Test, der 2014 durchgeführt wurde und den bei dieser Gelegenheit angeblich zum ersten Mal eine Maschine bestanden hätte[27]University of Reading (2014): Turing Test success marks milestone in computing history. Online verfügbar unter http://www.reading.ac.uk/news-and-events/releases/PR583836.aspx, zuletzt geprüft am … Continue reading. Es geht hierbei wohl eher um die mediale Aufmerksamkeit für die Veranstalter, als um wissenschaftliche Erkenntnis.
Alternativen zum Turing-Test
Neben den oben genannten Versuchen, den Turing-Test zu erweitern oder verbessern haben sich einige Forscher angesichts der teils vernichtenden Kritik am Turing-Test auf die Suche nach besseren Tests für maschinelle Intelligenz gemacht.
Seit ca. 2000 haben insbesondere Hernandez-Orallo[28]Hernández-Orallo, José (2000): Beyond the Turing test. In: Journal of Logic, Language and Information 9 (4), S. 447–466. und Bringsjord[29]Bringsjord, Selmer; Schimanski, Bettina (2003): What is artificial intelligence? Psychometric AI as an answer. In: IJCAI. Citeseer, S. 887–893. Vorschläge für psychometrische Tests gemacht – als Alternative zum Turing-Test. Sie kehren damit zurück zu der eigentlichen Frage, was Intelligenz eigentlich ist. Der Turing-Test war im Grunde Test und Definition zugleich – er hatte das Definitions-Problem übersprungen, es aber damit nicht gelöst. Hernandez-Orallo und Dowe stellen treffend klar wie es eigentlich laufen sollte:
„From an engineering point of view, the most desirable sequence of events would be to have a definition, then a feasible measurement procedure, and from these, to build intelligent systems that could be ultimately certified and evaluated with the measurement procedure.“[30]Hernández-Orallo, José; Dowe, David L. (2010): Measuring universal intelligence: Towards an anytime intelligence test. In: Artificial Intelligence 174 (18), S. 1508–1539.
Die psychometrischen Tests gehen von bekannten Definitionen von Intelligenz aus und messen die definierten (quantifizierbaren) Eigenschaften von Intelligenz. Bringsjord und Schimanski sehen als Ziel eine Vielzahl von Tests die verschiedene Aspekte von Intelligenz berücksichtigen[31]Bringsjord, Selmer; Schimanski, Bettina (2003): What is artificial intelligence? Psychometric AI as an answer. In: IJCAI. Citeseer, S. 887–893.. Hernandez-Orallo und Dowe präsentieren sogar bereits einen Ansatz für einen „universellen“ Intelligenztest der sowohl für Menschen wie auch Maschinen anwendbar ist[32]Hernández-Orallo, José; Dowe, David L. (2010): Measuring universal intelligence: Towards an anytime intelligence test. In: Artificial Intelligence 174 (18), S. 1508–1539..
Fazit
Man kann (wie Moor) einen erfolgreichen Test als Indiz für menschliche Intelligenz auffassen oder es (wie Searle) auch lassen. Es gibt gute Gründe für beide Seiten. Die grundlegende Frage „was ist (menschliche) Intelligenz“ beantwortet der Test leider nicht. Der Standard-Turing-Test ist damit nicht der große Durchbruch und diese Erkenntnis setzt sich auch überwiegend durch.
Für mich ist damit klar: wer sich wirklich mit KI beschäftigen will, sollte sich nicht mit dem Turing-Test beschäftigen. Dieser hat seine goldene Zeit schon lange hinter sich.
Aber: der Turing-Test ist aus Geschichte, Philosophie und Kunst nicht mehr wegzudenken. Er wird noch sehr, sehr lange immer wieder Erwähnung finden – als Inspiration oder Ablenkung.
References
| ↑1 | French, Robert M. (2000): The Turing Test: the first 50 years. In: Trends in cognitive sciences 4 (3), S. 115–122. |
|---|---|
| ↑2 | Epstein, Robert; Roberts, Gary; Beber, Grace (Hg.) (2009): Parsing the Turing test. Philosophical and methodological issues in the quest for the thinking computer: Springer. |
| ↑3 | Saygin, Ayse Pinar; Cicekli, Ilyas; Akman, Varol (2000): Turing test: 50 years later. In: Minds & Machines 10 (4), S. 463–518. |
| ↑4 | Weizenbaum, Joseph (1966): ELIZA — a Computer Program for the Study of Natural Language Communication Between Man and Machine. In: Commun. ACM 9 (1), S. 36–45. DOI: 10.1145/365153.365168. |
| ↑5, ↑9 | Hayes, Patrick; Ford, Kenneth (1995): Turing test considered harmful. In: IJCAI (1), S. 972–977 |
| ↑6, ↑17, ↑18 | Moor, James H. (2001): The status and future of the Turing test. In: Minds & Machines 11 (1), S. 77–93. |
| ↑7, ↑28 | Hernández-Orallo, José (2000): Beyond the Turing test. In: Journal of Logic, Language and Information 9 (4), S. 447–466. |
| ↑8 | Searle, John R. (1980): Minds, brains, and programs. In: Behavioral and brain sciences 3 (3), S. 417–424. |
| ↑10 | Whitby, Blay (1996): The turing test: AI’s biggest blind alley?’. In: Machines and thought: The legacy of Alan Turing 1, S. 53–62. |
| ↑11 | Turing, Alan M. (1950): Computing machinery and intelligence. In: Mind 59 (236), S. 433–460. |
| ↑12 | Weizenbaum, Joseph (1978): Die Macht der Computer und die Ohnmacht der Vernunft. 1. Aufl. Frankfurt am Main: Suhrkamp (Suhrkamp-Taschenbücher Wissenschaft, 274). |
| ↑13 | Bringsjord, Selmer (2009): If I Were Judge. In: Robert Epstein, Gary Roberts und Grace Beber (Hg.): Parsing the Turing test. Philosophical and methodological issues in the quest for the thinking computer: Springer, S. 89–102. |
| ↑14 | Turing, Alan M. (2009): Computing machinery and intelligence (Commented). Philosophical and methodological issues in the quest for the thinking computer. In: Robert Epstein, Gary Roberts und Grace Beber (Hg.): Parsing the Turing test. Philosophical and methodological issues in the quest for the thinking computer: Springer. |
| ↑15 | Sterrett, Susan G. (2000): Turing’s two tests for intelligence. In: Minds & Machines 10 (4), S. 541–559. DOI: 10.1023/A:1011242120015. |
| ↑16, ↑21 | Harnad, Stevan (2000): Minds, Machines and Turing. In: Journal of Logic, Language and Information (9), S. 425–445. |
| ↑19 | Warwick, Kevin; Shah, Huma (2016): Passing the turing test does not mean the end of humanity. In: Cognitive computation 8 (3), S. 409–419. |
| ↑20 | Harnad, Stevan (1994): Levels of functional equivalence in reverse bioengineering. In: Artificial Life 1 (3), S. 293–301. |
| ↑22 | Bringsjord, Selmer; Bello, Paul; Ferrucci, David (2001): Creativity, the Turing test, and the (better) Lovelace test. In: Minds and machines (11), S. 3–27. |
| ↑23 | Damassino, Nicola (2020): The Questioning Turing Test. In: Minds & Machines 30 (4), S. 563–587. DOI: 10.1007/s11023-020-09551-6. |
| ↑24 | Ahn, Luis von; Blum, Manuel; Hopper, Nicholas J.; Langford, John (2003): CAPTCHA: Using hard AI problems for security. In: International conference on the theory and applications of cryptographic techniques. Springer, S. 294–311. |
| ↑25 | Mauldin, Michael L. (1994): Chatterbots, tinymuds, and the turing test: Entering the loebner prize competition. In: AAAI, Bd. 94, S. 16–21. |
| ↑26 | Shieber, Stuart M. (1992): Lessons from a restricted turing test. Cambridge, Mass.: Center for Research in Computing Techn. Aiken Computation Laboratory Univ (TR / Center for Research in Computing Technology, Harvard University, 92,19). |
| ↑27 | University of Reading (2014): Turing Test success marks milestone in computing history. Online verfügbar unter http://www.reading.ac.uk/news-and-events/releases/PR583836.aspx, zuletzt geprüft am 19.03.2018. |
| ↑29, ↑31 | Bringsjord, Selmer; Schimanski, Bettina (2003): What is artificial intelligence? Psychometric AI as an answer. In: IJCAI. Citeseer, S. 887–893. |
| ↑30, ↑32 | Hernández-Orallo, José; Dowe, David L. (2010): Measuring universal intelligence: Towards an anytime intelligence test. In: Artificial Intelligence 174 (18), S. 1508–1539. |